Lab 9: Cluster and Cox processes
This session is concerned with summary statistics for interpoint spacing and distances. The lecturer’s R script is available here (right click and save).
library(spatstat)
Exercise 1
The command rThomas generates simulated realisations of the Thomas model (‘modified Thomas cluster process’).
-
Read the help file.
See
help("rThomas"). -
Type
plot(rThomas(10, 0.05, 8))a few times, and interpret the results.replicate(3, plot(rThomas(10, 0.05, 8), main = ""))
A clustered process – on average 10 clusters with 8 points. The standard deviation of the cluster distribution is 0.05, so most points will be within distance 0.10 from their parent.
-
Experiment with the arguments of
rThomasto obtain point patterns that-
consist of a few, well-separated, very tight clusters of points;
-
look similar to realisations of a uniform Poisson process.
We get few clusters by reducing the intensity of the parent process (first argument). Tightly and separated clusters are obtained by reducing the standard deviation (second argument).
plot(rThomas(5, 0.01, 8), main = "")
If the are many clusters with a large standard deviation it looks like Poisson.
plot(rThomas(100, 1, 1), main = "")
-
Exercise 2
-
Read the help file for
kppm.See
help("kppm"). -
Fit the Thomas model to the
redwooddata by the method of minimum contrast:fit <- kppm(redwood ~ 1, clusters="Thomas") fit plot(fit)From the documentation, the minmum contrast fitting procedure is default. Hence, we need not specify it.
fit <- kppm(redwood ~ 1, clusters = "Thomas") fit## Stationary cluster point process model ## Fitted to point pattern dataset 'redwood' ## Fitted by minimum contrast ## Summary statistic: K-function ## ## Uniform intensity: 62 ## ## Cluster model: Thomas process ## Fitted cluster parameters: ## kappa scale ## 23.5511449 0.0470461 ## Mean cluster size: 2.632568 pointsplot(fit, main = "", pause = FALSE)## Warning in density.ppp(locations, kernel = model, ...): Bandwidth selection ## will be based on Gaussian kernel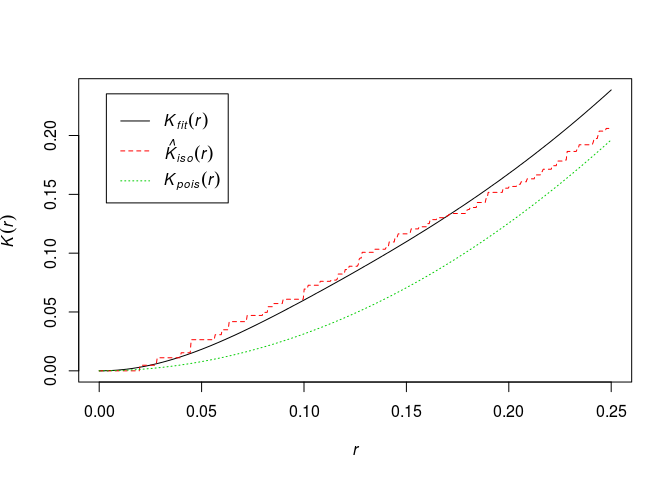
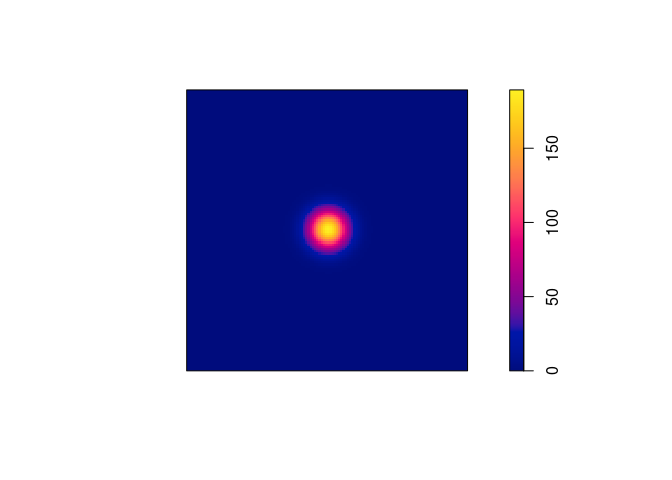
-
Read off the parameters of the fitted model, and generate a simulated realisation of the fitted model using
rThomas.From the previous output, we can read off the parameters to do the simulation (or we can use
parametersto extract them):(p <- parameters(fit))## $trend ## [1] 62 ## ## $kappa ## [1] 23.55114 ## ## $scale ## [1] 0.0470461 ## ## $mu ## [1] 2.632568rt2 <- rThomas(kappa = p$kappa, scale = p$scale, mu = p$mu) plot(rt2, main = "")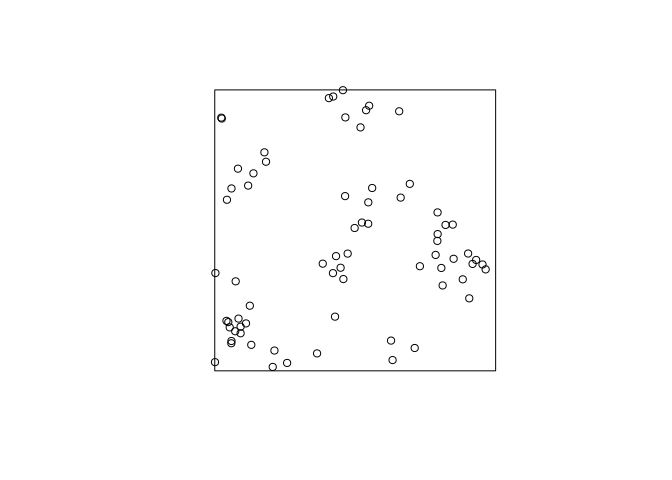
-
Type
plot(simulate(fit))to generate a simulated realisation of the fitted model automatically.OK, let try that alternative:
plot(simulate(fit, drop = TRUE), main = "")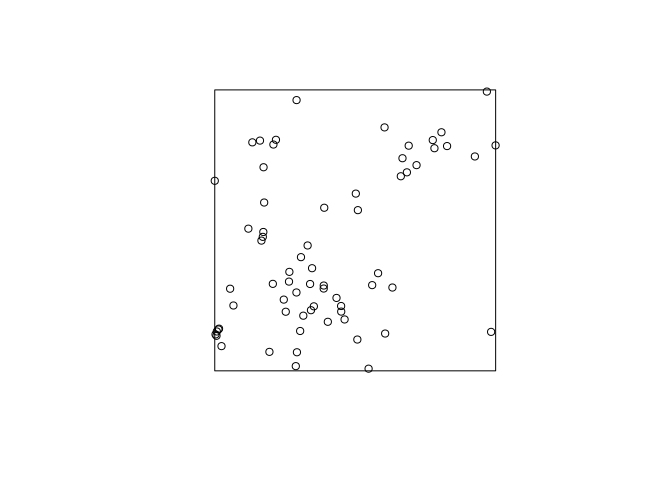
-
Try the command
fit2 <- kppm(redwood ~ 1, clusters="Thomas", startpar=c(kappa=10, scale=0.1))and briefly explore the fitting algorithm’s sensitivity to the initial guesses at the parameter values
kappaandscale.For “large” kappa (parent intensity) and “small” scale (standard deviation), the algorithm seems quite robust:
kppm(redwood ~ 1, clusters="Thomas", startpar=c(kappa=10, scale=0.1))## Stationary cluster point process model ## Fitted to point pattern dataset 'redwood' ## Fitted by minimum contrast ## Summary statistic: K-function ## ## Uniform intensity: 62 ## ## Cluster model: Thomas process ## Fitted cluster parameters: ## kappa scale ## 23.54757642 0.04704921 ## Mean cluster size: 2.632967 pointskppm(redwood ~ 1, clusters="Thomas", startpar=c(kappa=100, scale=0.01))## Stationary cluster point process model ## Fitted to point pattern dataset 'redwood' ## Fitted by minimum contrast ## Summary statistic: K-function ## ## Uniform intensity: 62 ## ## Cluster model: Thomas process ## Fitted cluster parameters: ## kappa scale ## 23.54962713 0.04705395 ## Mean cluster size: 2.632738 pointsHowever, for a very small parent intensity (kappa) and large offspring scale the fit changes considerably.
kppm(redwood ~ 1, clusters="Thomas", startpar=c(kappa=0.1, scale=10))## Stationary cluster point process model ## Fitted to point pattern dataset 'redwood' ## Fitted by minimum contrast ## Summary statistic: K-function ## ## Uniform intensity: 62 ## ## Cluster model: Thomas process ## Fitted cluster parameters: ## kappa scale ## 0.001824317 9.427722055 ## Mean cluster size: 33985.33 points -
Generate and plot several simulated realisations of the fitted model, to assess whether it is plausible.
XX <- simulate(fit, nsim = 11)## Generating 11 simulations... 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11. ## Done.XX[[12]] <- redwood plot(XX, main = "", main.panel = "")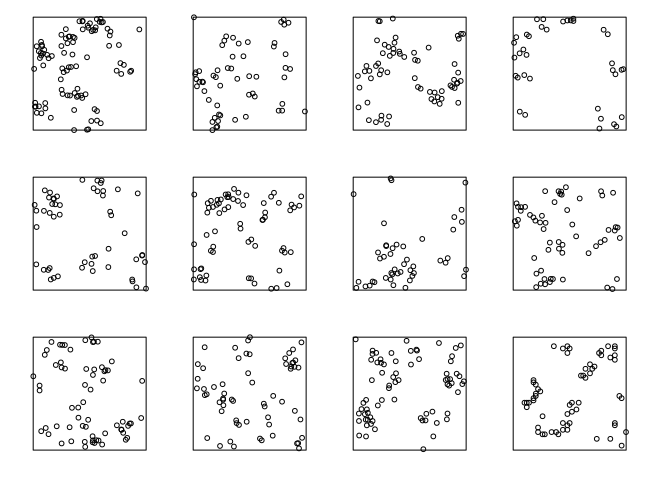
The actual data do not look too different from the simulated (apart from the artificial discretisation in the real data which can be seen on larger plots).
-
Extract and plot the fitted pair correlation function by
pcffit <- pcfmodel(fit) plot(pcffit, xlim = c(0, 0.3))OK, let’s try that:
pcffit <- pcfmodel(fit) plot(pcffit, xlim = c(0, 0.3), main = "pair correlation")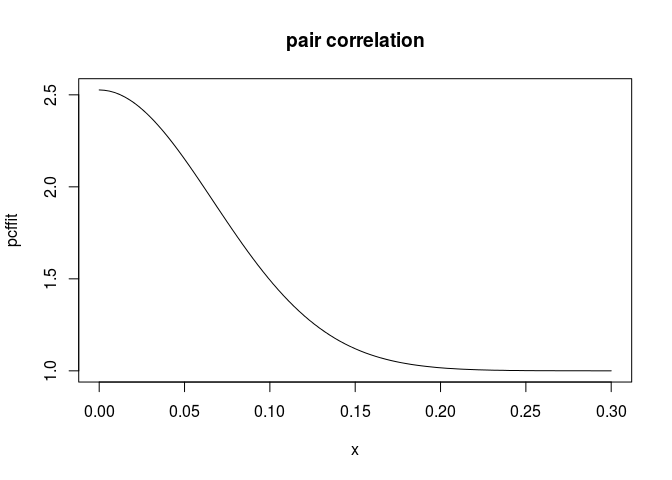
-
Type
plot(envelope(fit, Lest, nsim=39))to generate simulation envelopes of the L function from this fitted model. Do they suggest the model is plausible?plot(envelope(fit, Lest, nsim = 39, global = TRUE))## Generating 78 simulated realisations of fitted cluster model (39 to ## estimate the mean and 39 to calculate envelopes) ... ## 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, ## 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, ## 77, 78. ## ## Done.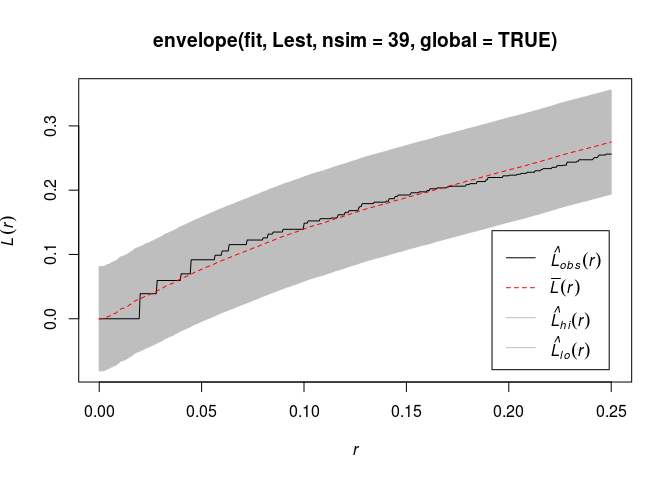
Yes, the model seems plausible and it does not devivated from the envelope.
Exercise 3
-
Fit a Matern cluster process to the
redwooddata.We fit the Matern cluster process by specifying the
clustersargument to beMatClust.mfit <- kppm(redwood ~ 1, clusters = "MatClust") -
Use
vcovto estimate the covariance matrix of the parameter estimates.The variance (covariance matrix) is computed straightforwardly:
vcov(mfit)## (Intercept) ## (Intercept) 0.05304008 -
Compare with the covariance matrix obtained when fitting a homogeneous Poisson model.
vcov(ppm(redwood ~ 1))## log(lambda) ## log(lambda) 0.01612903As can be seen, the variance of the intensity estimate is quite a bit larger in the Matern model. This comes naturally by the doubly stochastic construction of the Matern model.